


Мы обсудим следующие проблемы:
- Кластер ради кластера.
- Единые точки отказа.
- Нарушение принципов majority.
- Несимметричный кластер.
- Перегруженный кластер.
- Непротестированный кластер.
- Беспризорный кластер (без обслуживания и мониторинга).
Для подготовки материала мы использовали вебинар «10 типичных ошибок при разворачивании кластера». В выступлении спикер разобрал ещё три проблемы, а также ответил на вопросы зрителей. Если интересно, можно посмотреть вебинар, кликнув на его название.
1. Кластер ради кластера
Распространённая ошибка — разворачивать кластер тогда, когда он… Не нужен.Считается, что кластер — универсальный инструмент, который обеспечивает надёжность и отказоустойчивость системы. Отказоустойчивость в «айтишном» мире измеряют девятками:
- Одна девятка = доступность 90%. Это означает, что сервис может не работать 36 дней и 12 часов в год.
- Две девятки = доступность 99%. Сервис может не работать 87 часов и 46 минут в год.
- Три девятки = доступность 99.9%. Сервис может не работать 8 часов и 46 минут в год.
- Четыре девятки = доступность 99.99%. Сервис может не работать 52 минуты и 33 секунды в год.
- Пять девяток = доступность 99.999%. Сервис может не работать 5 минут и 35 секунд в год.
- Шесть девяток = доступность 99.9999%. Сервис может не работать всего 31,5 секунды в год.
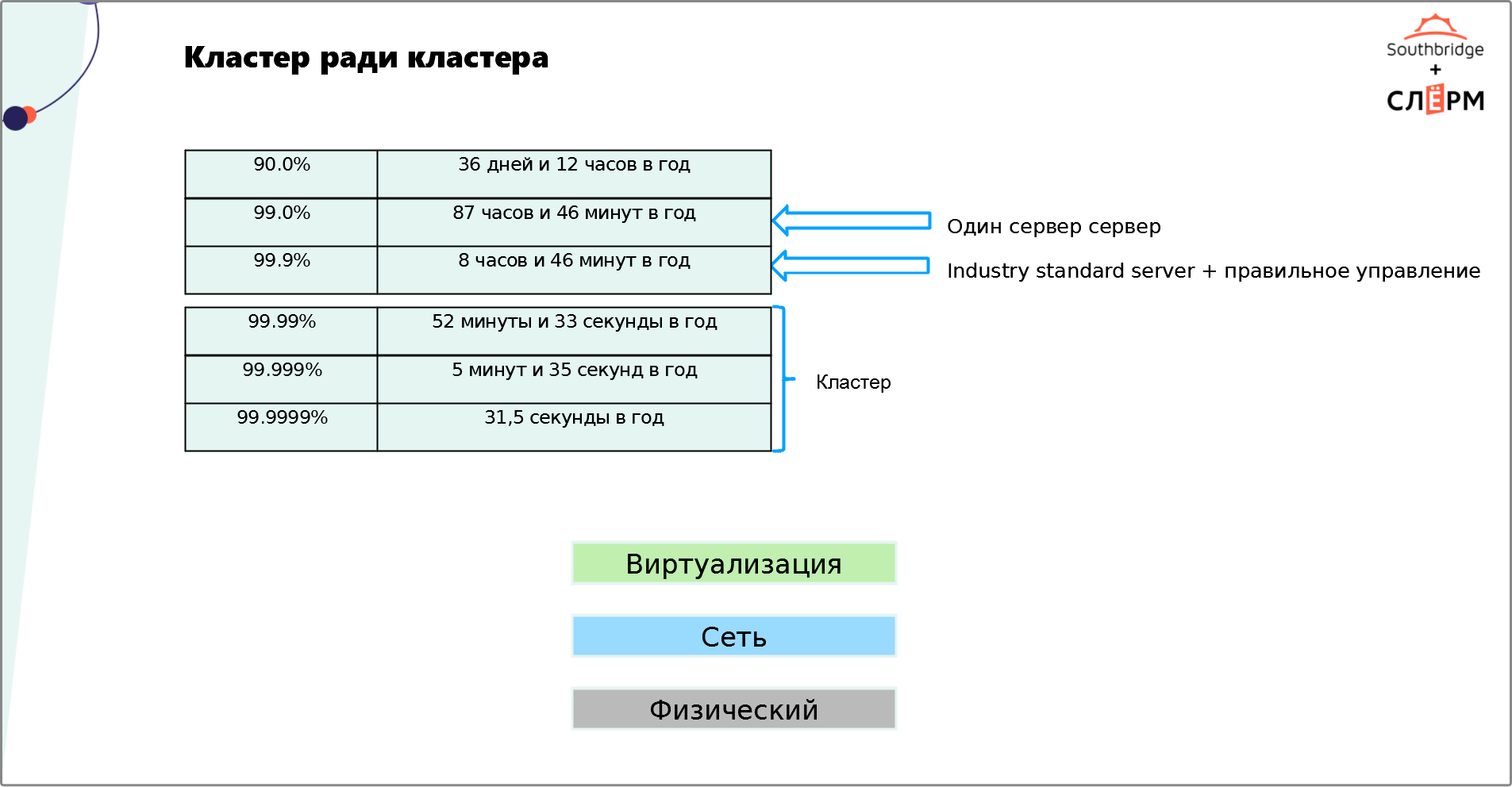
Большинству бизнесов для стабильной работы сервиса хватит трёх девяток. Чтобы их достичь, можно:
- Использовать Industry standard server, у которых дублируются жёсткие диски, сетевые карты, источники питания.
- Правильно его обслуживать: мониторить и принимать меры, когда сервер выходит из строя.
- Обеспечить отказоустойчивость дополнительными средствами. Например, подключить два источника питания от разных подов в дата-центре; подсоединить серверы к разным свитчам разными линками; делать агрегацию; сделать виртуализацию — она позволит абстрагироваться от проблем с железом.
Ни один сервер не обеспечит отказоустойчивость больше трёх девяток. Для такой доступности приложения нужно разворачивать кластер. Однако часто не учитывают, что это дорогое и сложное решение, для которого требуются:
- Дополнительные траты на покупку или аренду железа и ПО. Высокая отказоустойчивость нуждается в избыточности ресурсов — в нескольких серверах, виртуальных машинах и т. д.
- Больше операционных затрат. Дублируются траты на обслуживание ресурсов — необходимо обновлять две ОС, защищать два сервера с двумя приложениями и т. д.
- Специалисты достаточно высокого уровня для поддержки кластера. Рядовой сисадмин с этим вряд ли справится.
Прежде чем внедрять кластер, следует:
- Понять, какая отказоустойчивость приложения необходима для вашего бизнеса.
- Посчитать, сколько денег вы теряете в случае простоя.
- Сопоставить траты на внедрение и содержание кластера с суммой, которую вы теряете при простое системы.
Если кластер стоит дороже времени простоя, то разворачивать его нерентабельно. Можно обойтись тремя девятками, укрепив отказоустойчивость средствами, о которых мы рассказали выше.
2. Единые точки отказа
Если заранее не продумать архитектуру так, чтобы в ней не было единых точек отказа сервиса, расходы на кластер будут напрасными. Единые точки отказа — это узлы системы, выход из строя которых может привести к недоступности приложения:- Один источник питания на все серверные стойки.
- Единое для всех серверов хранилище.
- Firewall и устройства, которые находятся в пограничной зоне между пользователями и кластером.
- Сетевое оборудование: свитчи, роутеры.
- Load balancers.
- Серверы. Если все виртуальные машины находятся на одном сервере, при его отказе приложение тоже упадёт.
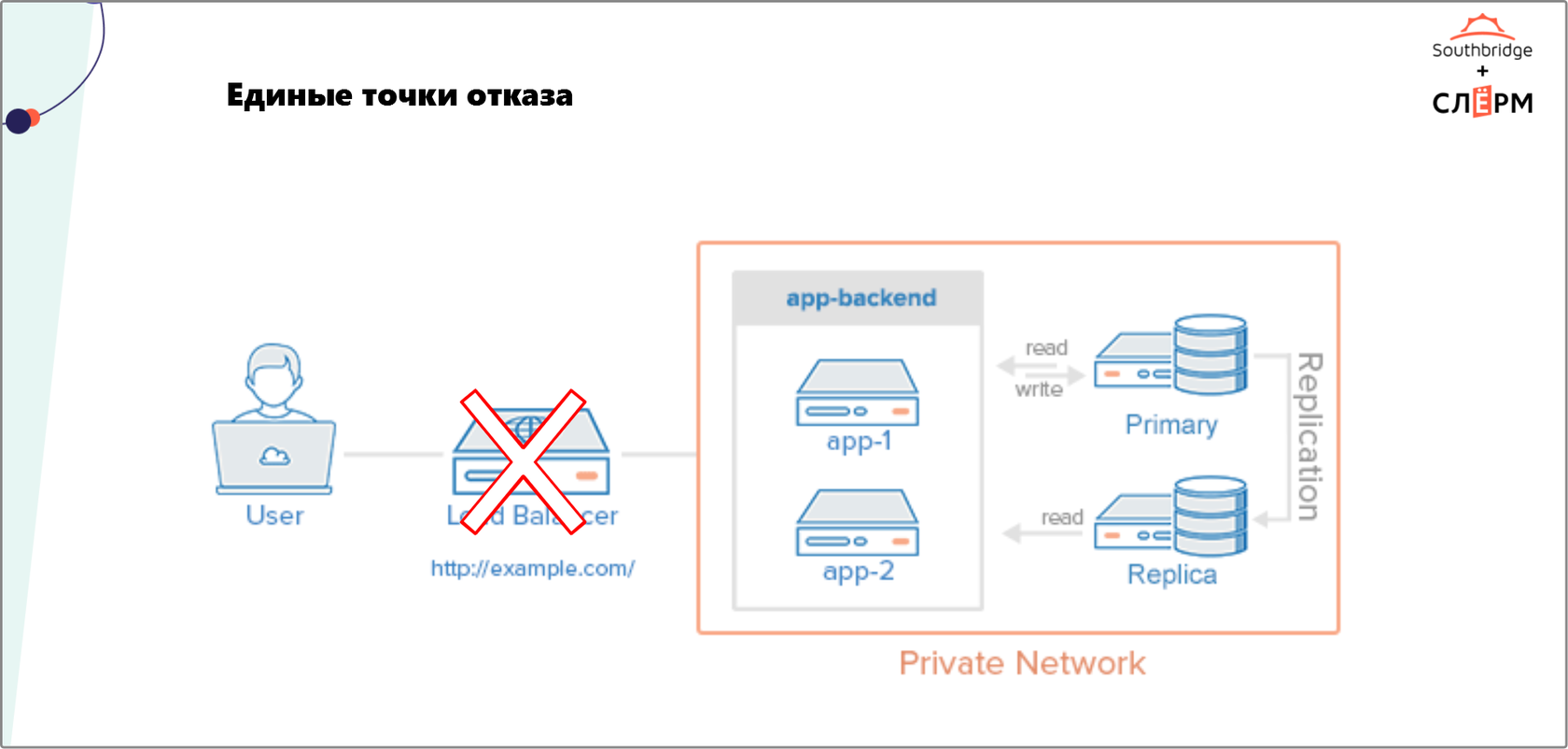
На Рис. 1 — не лучший пример отказоустойчивой архитектуры. Мы видим приложение с кластеризованными бэкендом и базой данных, а также Load balancer, выполняющим роль фронтенда. В этой схеме Load balancer — единая точка отказа. Если он сломается, пользователь не получит доступ к сервису, хотя серверы работают, а база данных отдаёт данные по запросу.
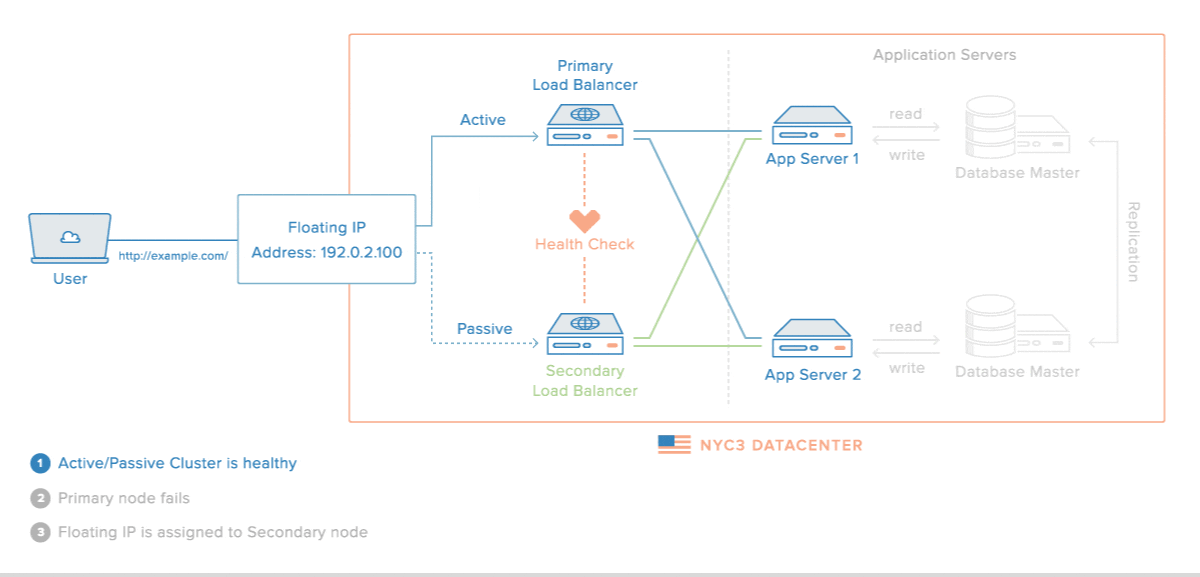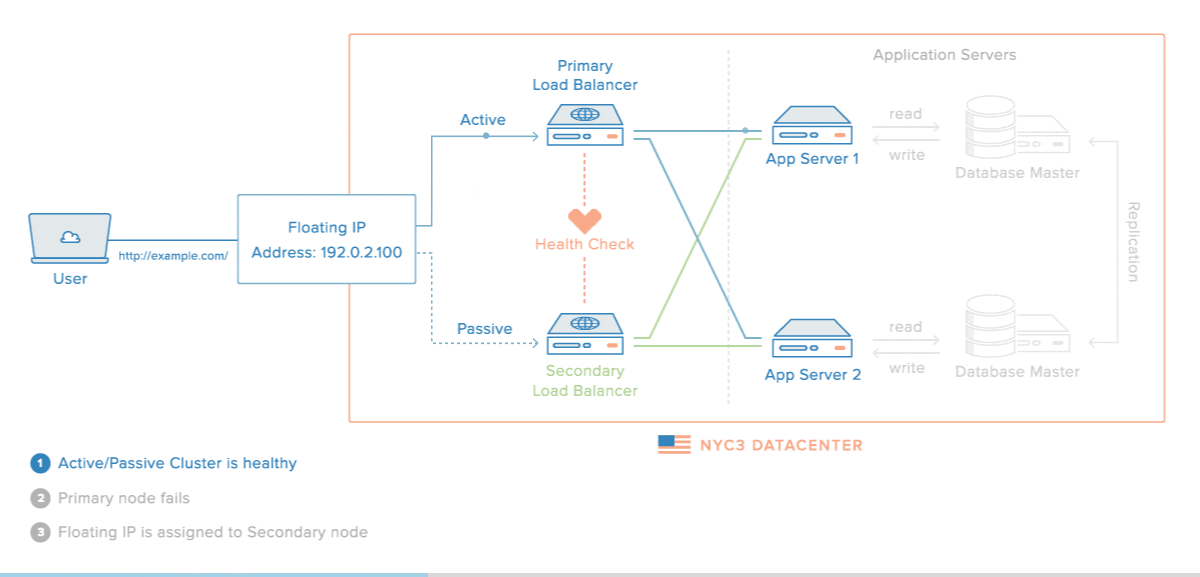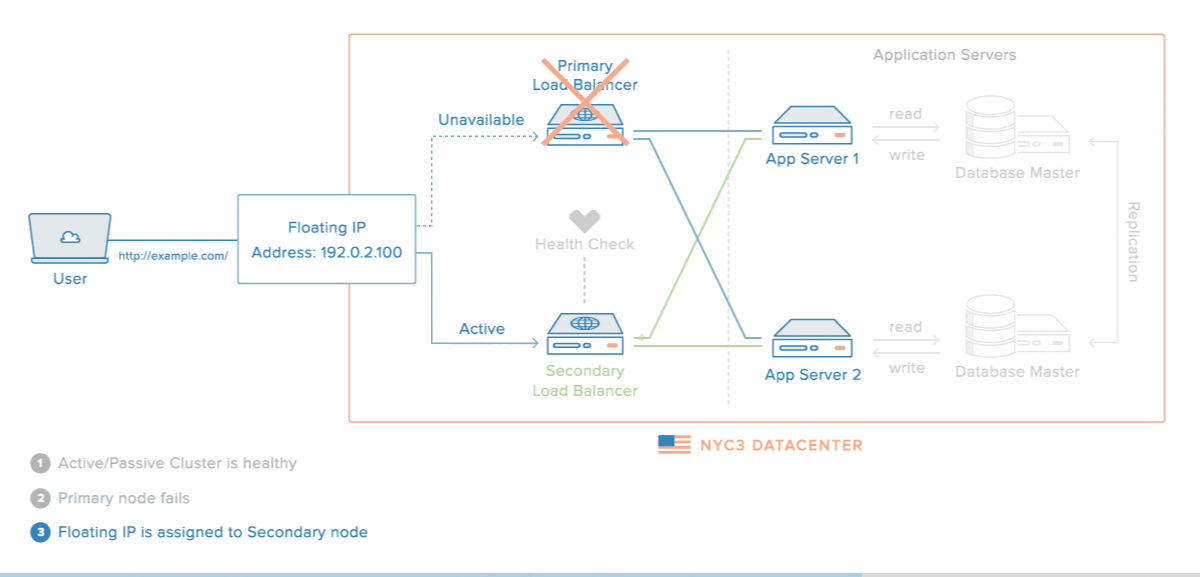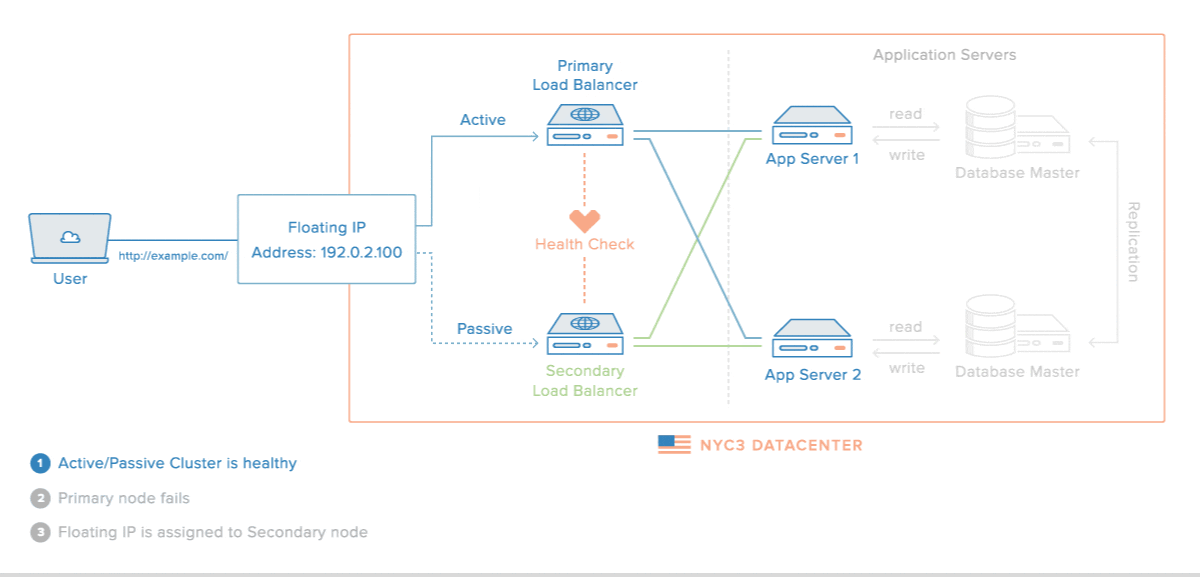
На Рис. 2 — кластер с высоким уровнем доступности. Здесь нет видимых точек отказа. IP-адрес плавает между Load balancers. Есть сервер приложения и кластеризованный сервер базы данных. Другие точки отказа на уровне инфраструктуры закрывает дата-центр.
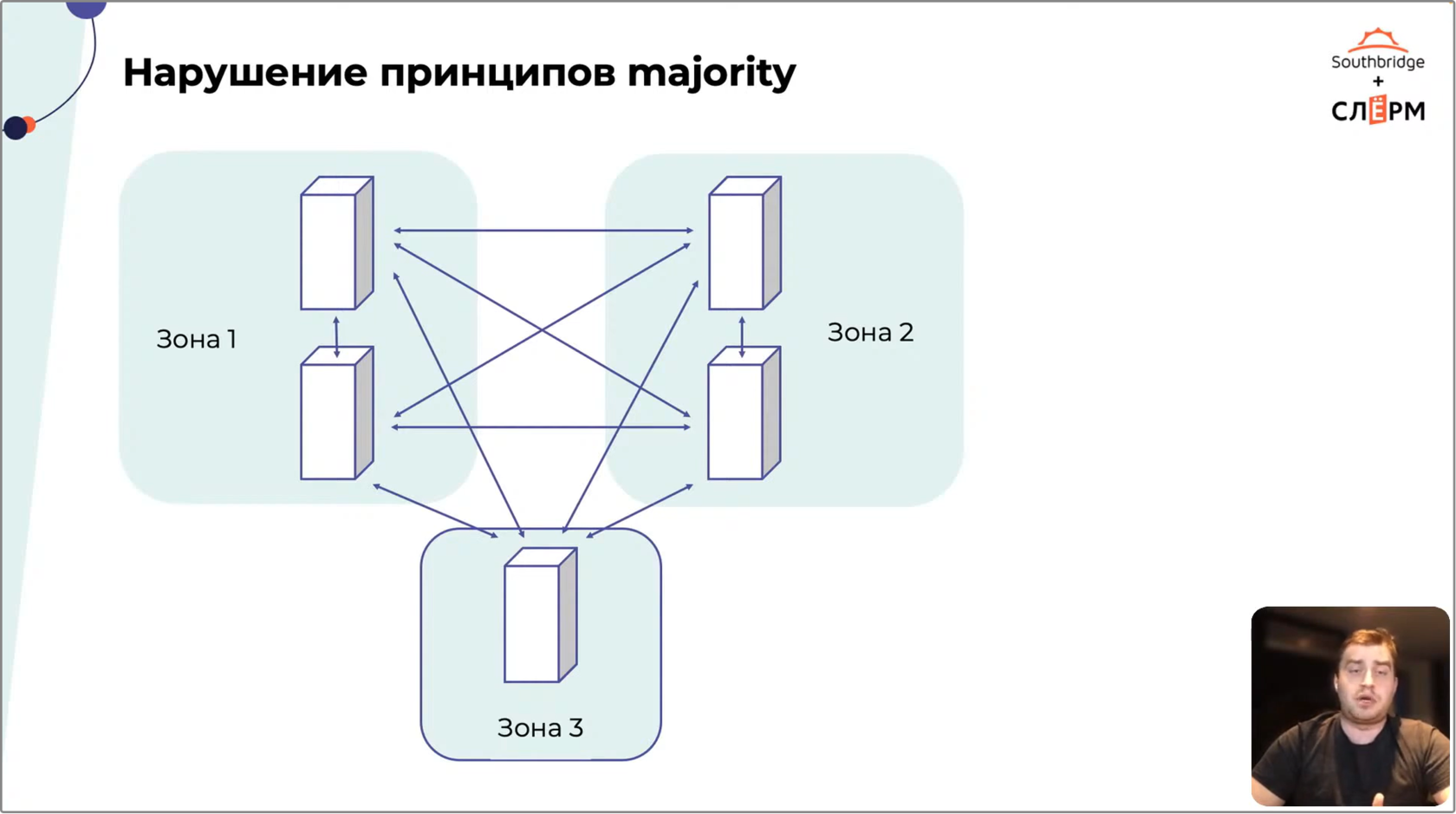
3. Нарушение принципов majority
Чтобы кластер автоматически отработал отказ узла, ему необходимо понять, что произошло. Нода упала или стала изолированной? Порвалась сеть? Чтобы это определить, большинство кластеров используют принцип majority. У каждой ноды есть «голос». Работать останется та часть кластера, у которой больше голосов.На Рис. 3 — кластер из трёх нод, распределённых по двум зонам отказа. В Зоне 1 — две ноды, следовательно, у этой зоны два «голоса». В Зоне 2 — одна нода и один «голос». Если вторая зона откажет, то кластер продолжит обслуживать Зона 1.
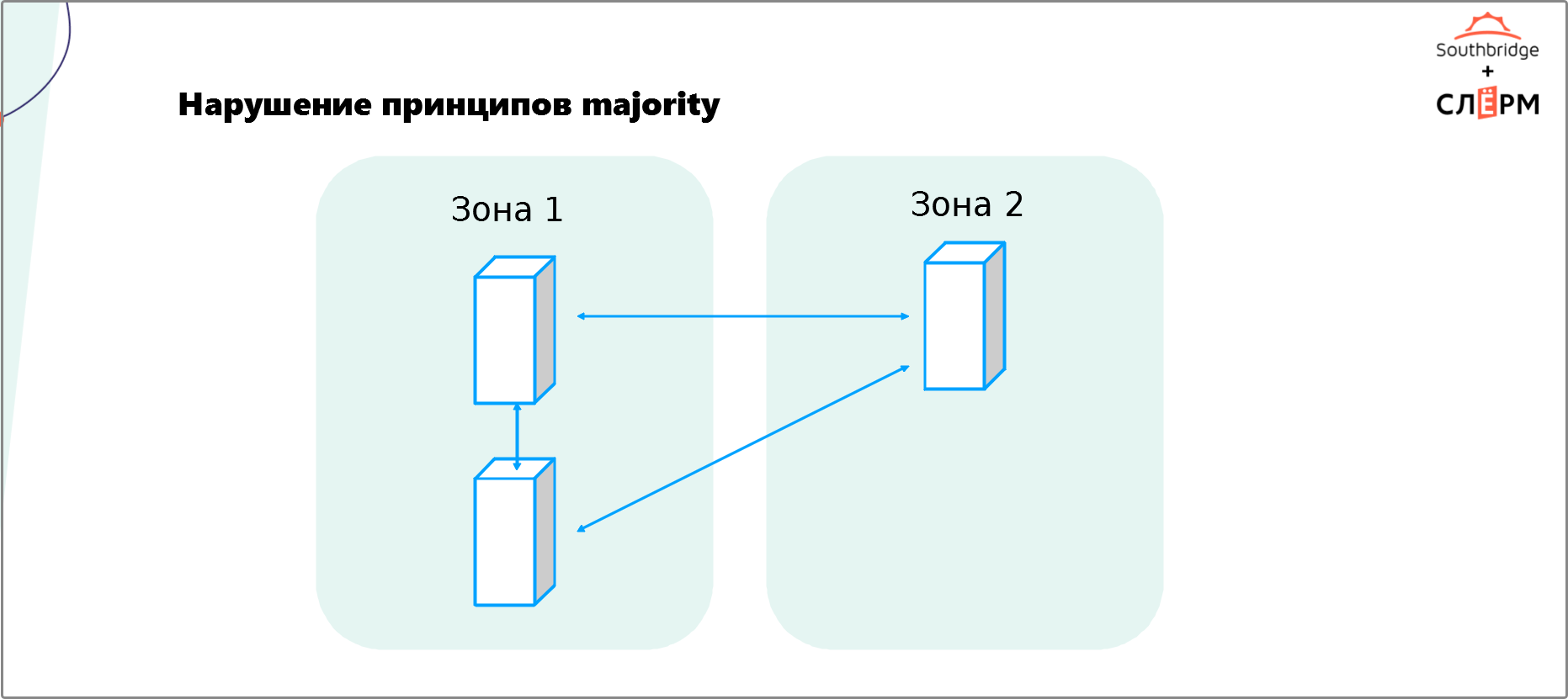
Кажется, что такая архитектура хорошо работает. Это не так — здесь нарушен принцип majority. Потеряв соединение с Зоной 1, Зона 2 не получит majority, посчитает себя изолированной от кластера и отключит сервис — приложение станет недоступным. Включать его придётся вручную, а на это потребуется время.
Если кластер состоит из чётного количества узлов, которые распределены в две зоны отказа, то разрыв соединения между ними приведёт к сплит-брейну (Split Brain). Кластер посчитает, что всё нормально и обе его части работают корректно, хотя это не так и зоны не «общаются» друг с другом.
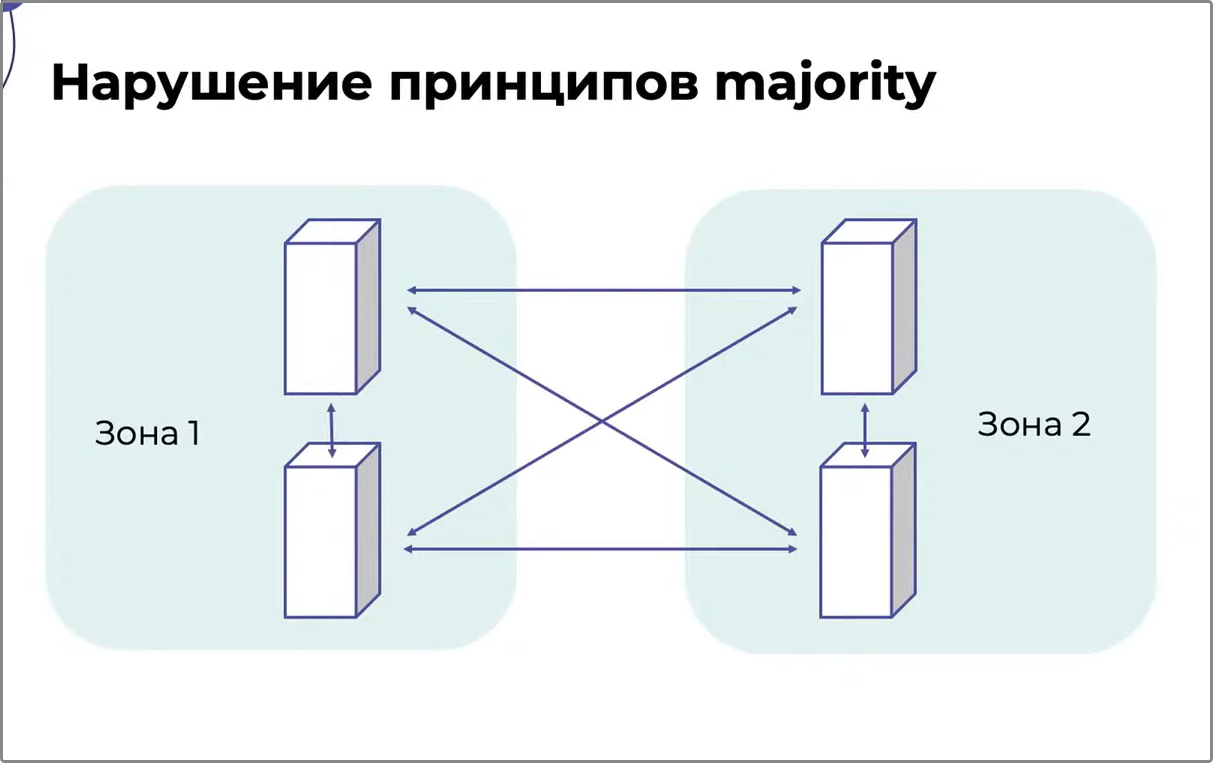
Сплит-брейн легко устраняется восстановлением соединения и не приводит к серьёзным последствиям при условии, что он произошёл не на кластере базы данных. В противном случае при обрыве сети кластер продолжает параллельно сохранять данные в обеих зонах и, когда между узлами снова появляется связь, начинается путаница — приходится долго разбираться, что записалось, а что потерялось; какие данные нужно удалить, а какие совместить. В связи с этим кластеры, особенно те, что хранят данные, рекомендуется дробить на нечётное количество зон отказа.
На Рис. 5 — кластер, в котором соблюдается принцип majority. Он состоит из 5 нод, распределённых по трём зонам отказа. Если первая зона отключится, Зона 2 продолжит видеть Зону 3 и наоборот, и кластер будет работать.
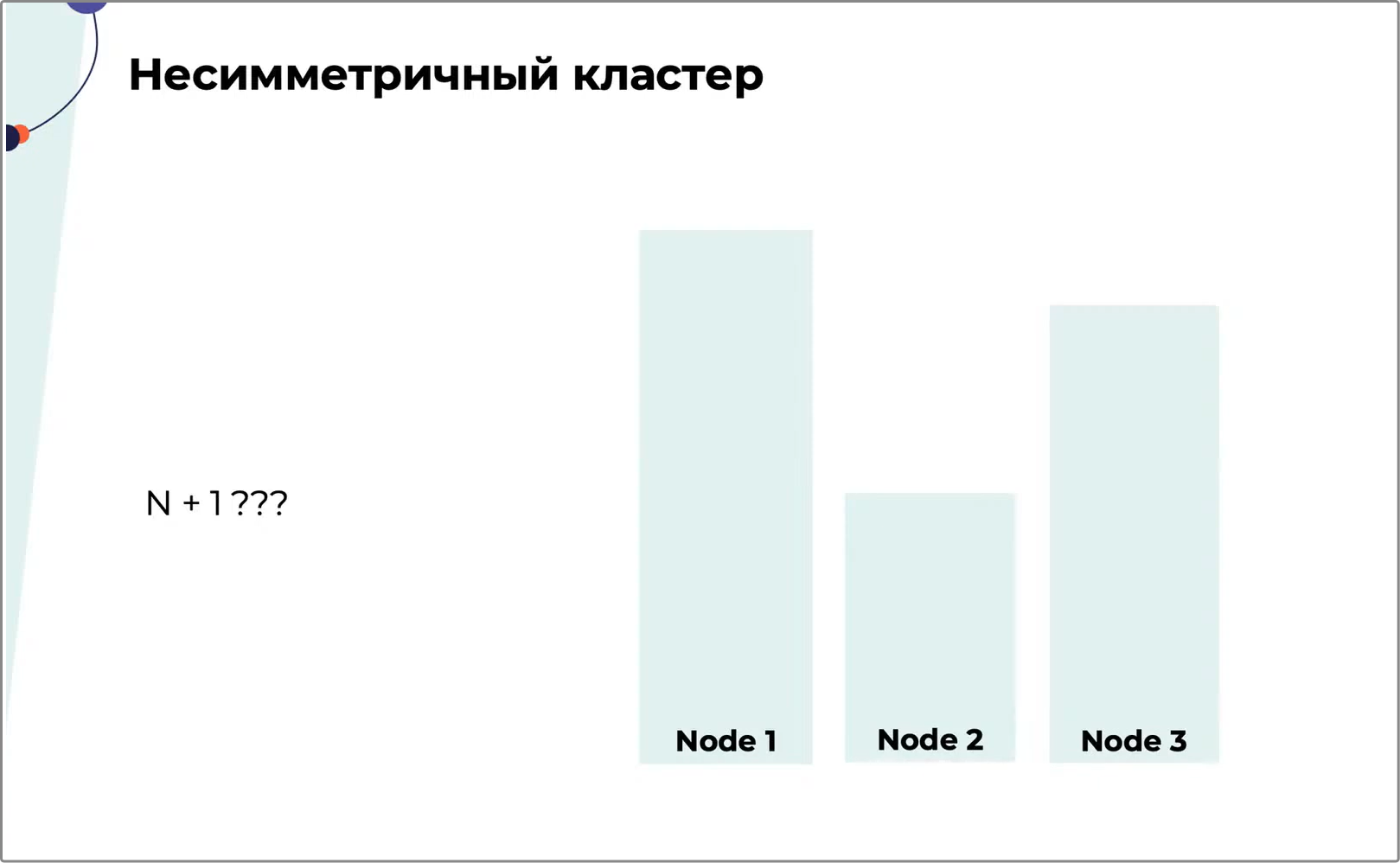
4. Несимметричный кластер
При внедрении кластера нужно позаботиться о его симметричности и выделить каждой ноде одинаковое количество ресурсов: ЦПУ, дисков, памяти и т. д. Так будет гораздо легче обеспечить отказоустойчивость и не загрузить кластер на 100% при отказе одной или нескольких нод. Приложение на 100% загруженном кластере работает так себе — в лучшем случае оно подтормаживает. В худшем — вообще не загружается.На Рис. 6 — несимметричный кластер. При падении второй ноды её ресурсы распределятся между нодами 1 и 3, и это не перегрузит кластер. Если откажет нода 1, её ресурсы не поместятся в ноды 2 и 3 — из строя выйдет весь кластер.
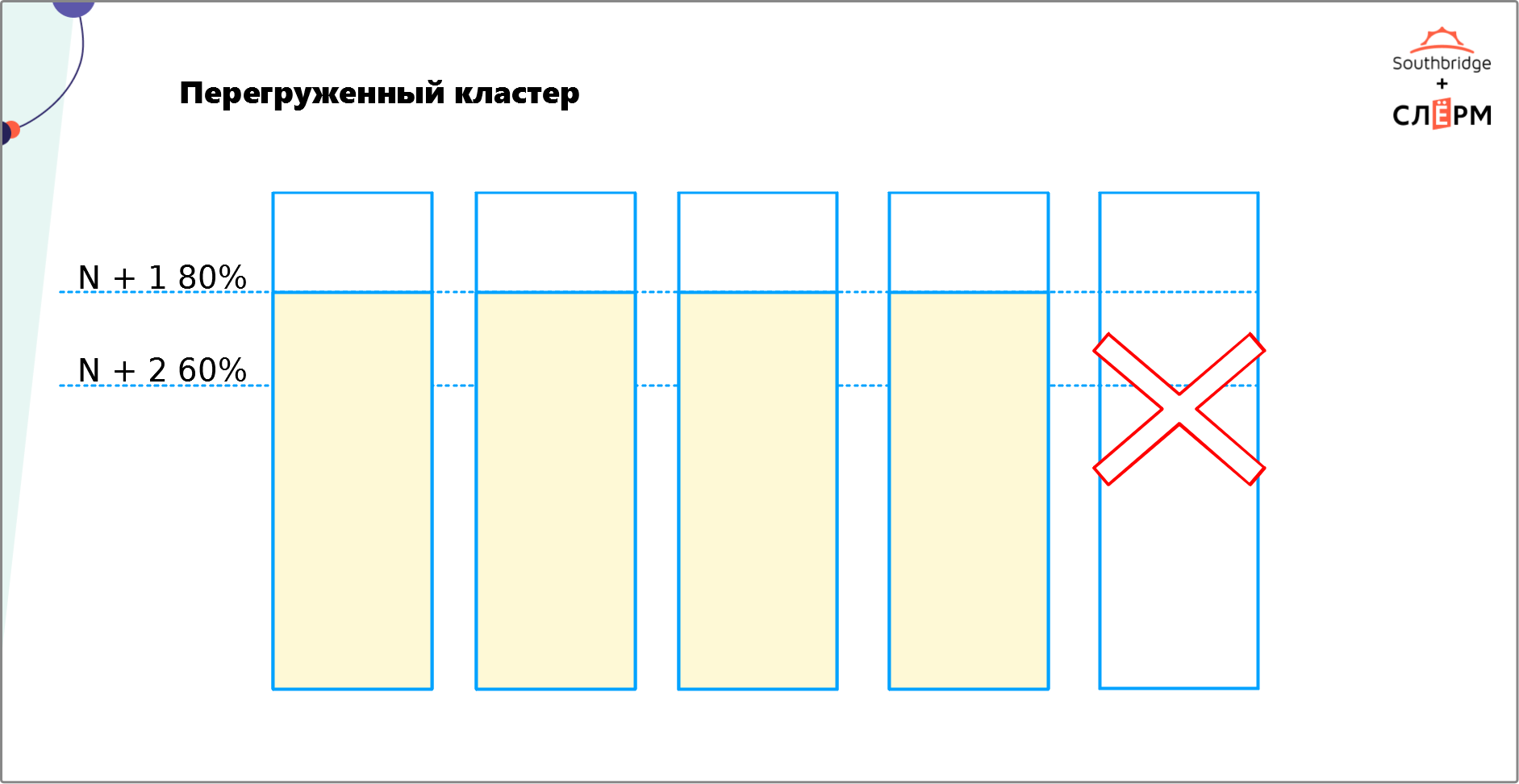
5. Перегруженный кластер
Эта ошибка связана с предыдущей. Выше мы уже говорили, что отказоустойчивый кластер требует избыточности. Это значит, что нужно не только равномерно распределить по нодам ЦПУ, диски, память и т. д., но и выделить на них некоторое количество ресурсов, которые не будут использоваться. Необязательно закладывать в два или три раза больше ресурсов. Их должно быть столько, чтобы хватило на рост нагрузки в случае отказа одной или нескольких нод и осталось ещё немного.На Рис. 7 — кластер из пяти нод. Мы хотим обеспечить N + 2 — сделать так, чтобы при отказе двух нод кластер продолжил работать. Сейчас кластер сможет распределить нагрузку при отказе одной ноды (Рис. 8), а вот двух — уже нет (Рис. 9).

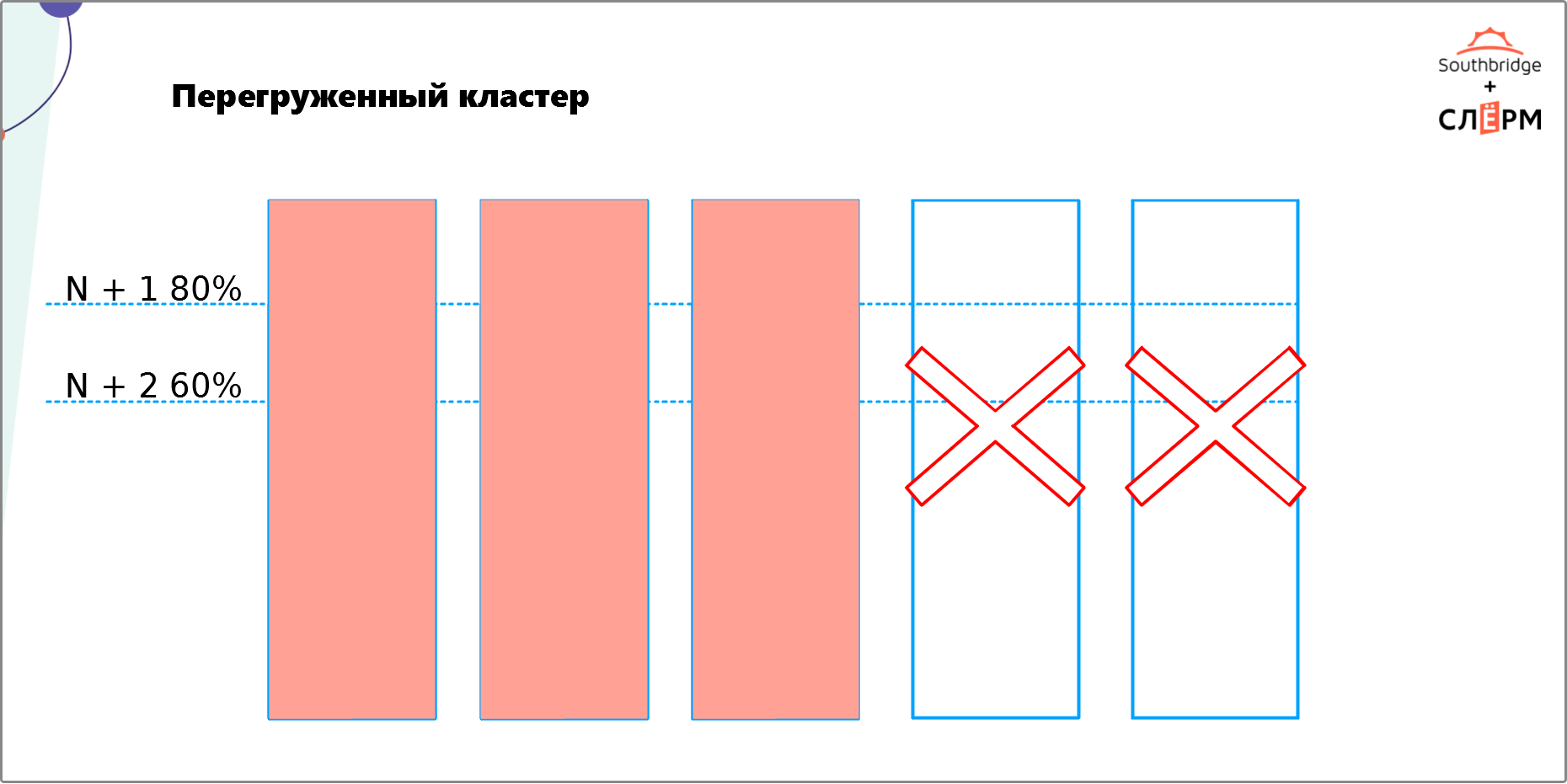
Чтобы обеспечить на таком кластере N + 2, нужно выделить столько ресурсов для каждой ноды, чтобы:
- при отказе одной ноды нагрузка на оставшиеся четыре составила не больше 60%;
- при отказе двух нод нагрузка на оставшиеся три составила не больше 80%.
6. Непротестированный кластер
Перед запуском следует протестировать кластер и убедиться, что он работает именно так, как мы ожидаем. В противном случае его поведение может стать неприятным сюрпризом — кластер может долго переключать сервис; падать, когда не должен; мешать решать другие задачи.Вот список вопросов, на которые стоит ответить при тестировании кластера:
- Сработает ли кластеризация в случае отказа?
- Сколько времени займёт переключение сервиса?
- Как подготовиться к плановому обслуживанию?
- Что делать, если часть инфраструктуры станет недоступна?
- Есть ли в серверной провод, выдернув который мы выключим весь кластер?
7. Беспризорный кластер (без обслуживания и мониторинга)
Чтобы стабильно работать и обеспечивать тот уровень отказоустойчивости, для которого он внедрялся, кластеру требуется мониторинг.Мониторинг позволяет:
- Выявить вышедший из строя компонент кластера раньше, чем из-за поломки сломается сам сервис.
- Доказать бизнесу, что деньги на кластер потрачены не зря и он обеспечивает ожидаемый уровень отказоустойчивости.
- Измерять и контролировать загрузку кластера, чтобы избежать несимметричности и перегруженности. Кластер не статичен. Со временем у него растёт загрузка, меняются версии и конфигурации.
Кроме того, перед запуском кластера в продакшн, нужно понять, каким образом его обслуживать с минимальным влиянием на доступность приложения. Если не разобраться с этим вопросом заранее, попытка закрыть баг или поднять новую версию может привести к простою системы.
Резюме
Мы прошлись по 7 основным ошибкам. На их основе можно выделить три главные вещи, которые следует сделать при внедрении кластера:- Ответить на вопрос: «Действительно ли нужен кластер?» Иногда достаточный уровень отказоусточивости обеспечивается без этого инструмента.
- Протестировать кластер перед запуском в продакшн и понять, как система ведёт себя в разных условиях, нет ли у неё единых точек отказа и нарушений принципов majority, равномерно ли распределены ресурсы и т. д.
- Обеспечить кластеру мониторинг и обслуживание.